Cum să realizezi prognoze de vânzări mai precise folosind tehnici de inteligență artificială - Part 4 - Analiza exploratorie a datelor
Introducere în analiza exploratorie a datelor
Analiza exploratorie a datelor (EDA) este un prim pas important în orice analiză a datelor. EDA este folosită pentru a analiza și investiga seturile de date și pentru a rezuma principalele caracteristici ale acestora, folosind adesea metode de vizualizare a datelor. EDA, de asemenea, poate ajuta la determinarea dacă tehnicile statistice pe care le luați în considerare pentru analiza datelor sunt adecvate.
Tipuri de analiză exploratorie a datelor
Nongrafic univariat: Aceasta este cea mai simplă formă de analiză a datelor, în care datele analizate constă dintr-o singură variabilă. Deoarece este o singură variabilă, nu se ocupă de cauze sau relații. Scopul principal al analizei univariate este de a descrie datele și de a găsi modele care există în ele.
Grafic univariat: Metodele nongrafice nu oferă o imagine completă a datelor. Prin urmare, sunt necesare metode grafice. Tipurile comune de grafice univariate includ:
Grafice care arată toate valorile datelor și forma distribuției.
Histograme, un grafic cu bare în care fiecare bară reprezintă frecvența (numărarea) sau proporția (numărarea/numărarea totală) cazurilor pentru un interval de valori.
Diagrame de tip boxplot, care descriu grafic rezumatul cu cinci numere de minim, prima cuartila, mediană, a treia cuartila și maxim.
Nongrafic multivariat: Datele multivariate provin din mai multe variabile. Tehnicile EDA negrafice multivariate arată în general relația dintre două sau mai multe variabile ale datelor prin tabele încrucișată sau statistici.
Grafică multivariată: datele multivariate utilizează grafice pentru a afișa relațiile dintre două sau mai multe seturi de date. Cel mai utilizat grafic este un diagramă cu bare grupate sau o diagramă cu bare, fiecare grup reprezentând un nivel al uneia dintre variabile și fiecare bară dintr-un grup reprezentând nivelurile celeilalte variabile [1]
Analiza descriptivă - Nongrafic univariata
Pentru analiza descriptivă non-grafică univariată vom folosi libraria Pandas, methoda ”describe”.
sales_describe = sales_data_df.describe()[['quantity']].round(2)

Aceste statistici oferă o imagine de ansamblu a distribuției variabilei respective. Iată cum se interpreta fiecare dintre aceste statistici:
Count: Numărul total de observații sau puncte de date din setul de date este de 913.
Mean (Media): Valoarea medie a variabilei este de 663.51. Aceasta reprezintă valoarea centrală a datelor, adică suma tuturor valorilor împărțită la numărul de observații.
Std (Deviația standard): Deviația standard este de 343.16. Acesta măsoară cât de mult se abat valorile individuale de la valoarea medie. Cu o deviație standard mai mare, datele sunt mai dispersate.
Min (Valoarea minimă): Valoarea minimă în setul de date este 0.0. Acesta reprezintă cea mai mică valoare observată.
Percentila 25%: La 25% din observații, valoarea variabilei este sub 470.61. Acest lucru indică faptul că 25% dintre date sunt mai mici decât acest număr.
Percentila 50% sau Mediană: Valoarea la care 50% din observații sunt mai mici și 50% sunt mai mari este de 623.59. Acesta este un indicator al valorii centrale a setului de date.
Percentila 75%: La 75% din observații, valoarea variabilei este sub 849.52. Acest lucru indică faptul că 75% dintre date sunt mai mici decât acest număr.
Max (Valoarea maximă): Valoarea maximă din setul de date este de 2151.1. Acesta reprezintă cea mai mare valoare observată.
Analiza descriptivă - Grafic univariat - Line Chart
Folosind o analiza descriptivă în contextul datelor seriei temporale se observă tendințele și sezonalitatea
fig = go.Figure()
fig.add_trace(
go.Scatter(
x=sales_prep_data['date'],
y=sales_prep_data['quantity'],
name='quantity')
)
fig.show()
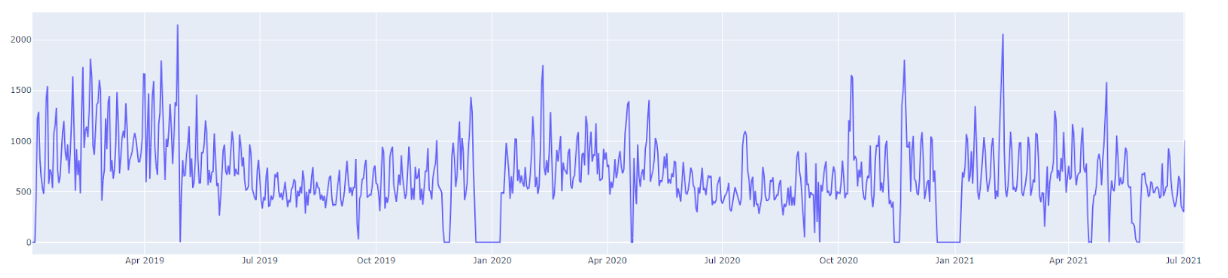
Evolutia în timp a vanzarilor
Tendințe (Trends): Analiza descriptiva identifica tendințele semnificative sau mișcările constante în date. O tendință poate fi crescută, scăzută sau stabilă în timp. Din datele de vanzari istorice putem identifica tendințe de scădere a evoluției pe termen mediu.

Cicluri (Cycles): Ciclurile reprezintă mișcările repetitive sau perioadele de creștere și scădere care pot apărea în date. Acestea pot avea o periodicitate variabilă și pot fi legate de factori economici sau sezonieri. Din datele de vanzari putem observa un ciclu repetitiv la nivel de an.

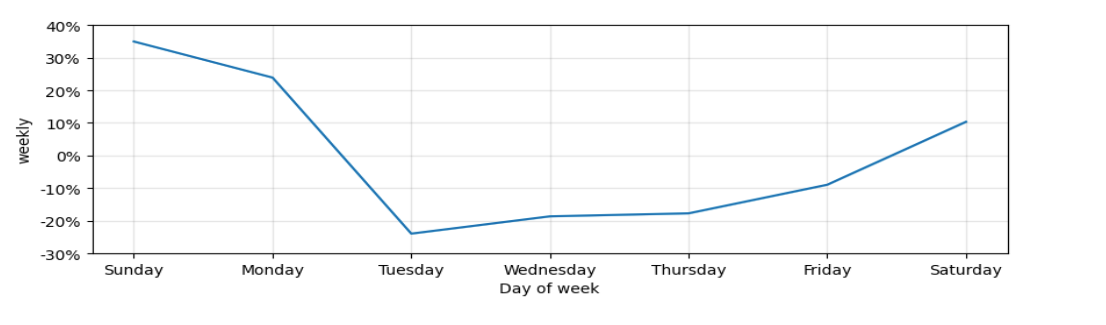
Variații Sezoniere (Seasonal Variations): Variațiile sezoniere descriu modelele care se repetă la intervale regulate, de obicei pe parcursul unui an. Acestea pot fi legate de evenimente sezoniere sau de ciclurile sezoniere în comportamentul datelor. Din datele istorice se observa ca exista o variatie puternica în vanzarii în funcție de anotimp și ziua saptamanii.
Analiza descriptivă - Grafic univariat - Violin Plot
Interpretarea rezultatelor dintr-un grafic tip violin cu date de vânzări implică înțelegerea distribuției și caracteristicilor datelor pentru fiecare categorie sau grup reprezentat în grafic.
Forma Graficului Violin: Forma graficului violin arată distribuția datelor de vânzări pentru fiecare categorie. O secțiune mai lată indică o densitate mai mare a vânzărilor, în timp ce o secțiune mai îngustă indică o densitate mai mică. Dacă graficul violin este simetric, sugerează o distribuție relativ echilibrată a vânzărilor în categoria respectivă.
Lățimea Graficului Violin: Lățimea graficului violin poate indica intervalul de valori de vânzări. O secțiune mai largă a graficului sugerează o gamă mai largă de valori de vânzări în acea categorie.
Linia Mediană: Linia din interiorul graficului violin reprezintă valoarea mediană a vânzărilor pentru fiecare categorie. Este o măsură a tendinței centrale a datelor.
Intervalul Interpercentilic (IQR): Lățimea părții centrale a graficului violin, cunoscută sub numele de "cutie," reprezintă intervalul interpercentilic (IQR). IQR este o măsură a dispersiei celor 50% din date situate în mijlocul distribuției.
Cozile și Extremele: "Cozile" graficului violin arată densitatea valorilor de vânzări în cozile sau valorile extreme ale distribuției. O coada mai lungă indică prezența valorilor extreme sau a outlier urilor.
Comparări Generale: Poți utiliza graficul violin pentru a compara distribuția datelor de vânzări între diferite categorii. De exemplu, dacă graficul pentru o categorie este semnificativ mai lat sau mai lung decât celelalte, acest lucru poate sugera o variație mai mare sau valori mai extreme.
Asimetrie: Asimetria graficului poate fi observată din forma acestuia. Dacă graficul este asimetric într-o direcție, sugerează că datele de vânzări au o asimetrie pozitivă sau negativă.
Estimarea Densității: Graficele violin includ adesea o estimare a densității kernel (KDE) care reprezintă curbura netedă din interiorul graficului violin. Acesta arată cum sunt distribuite valorile de vânzări în întregul interval.
sns.violinplot(
data=sales_prep_data[['quantity']],
bw_adjust=.5,
cut=1,
linewidth=1,
palette="Set3"
);
Analiza descriptivă - Grafic univariat - Gradul de autocorelație ACF
Funcția de AutoCorelație (ACF). ACF cuantifică corelația între o serie temporală și valorile sale întârziate la diferite întârzieri de timp (sau întârzieri), denumite "k." Ajută la înțelegerea structurii de dependență a datelor de-a lungul timpului.
ACF este calculată după cum urmează:
ACF(k) = γ(k) / γ(0)
ACF(k): Auto-Corelația la întârzierea "k."
γ(k): Auto-Covarianța la întârzierea "k."
γ(0): Auto-Covarianța la întârzierea "0."
După cum am menționat, ACF(0) este întotdeauna egal cu 1 deoarece covarianța unei serii cu ea însăși la aceeași întârziere este întotdeauna aceeași.
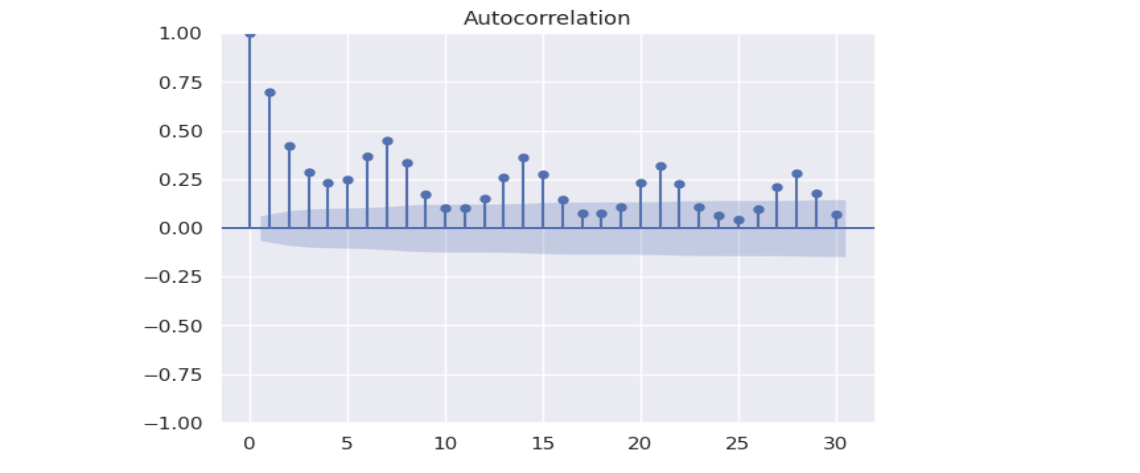
Întrebarea aici este de ce există o autocorelație atât de puternică la lag-urile 1, 2, 3, ...? Problema este că datele nu pot răspunde la această întrebare. Aceasta ar putea fie să fie o autocorelație cu adevărat aleatoare în serie, fie să existe un efect fix sau o tendință care nu a fost înlăturată (adică seria nu este staționară).
Acest tipar în graficul ACF este în mod obișnuit o indicație a non-staționarității, mai degrabă decât un semn al unei autocorelație. Dacă observați o astfel de tendință, ar trebui să verificați dacă seria dvs. temporală prezintă efecte fixe semnificative, cum ar fi o tendință liniară sau o componentă sezonieră. Dacă există astfel de efecte, acestea ar trebui eliminate în primul rând (de exemplu, prin modelarea regresiei) și apoi să refaceți graficul ACF.
Analiza descriptivă - Grafic univariat - Histograma
Histograma este o metodă eficientă pentru a vizualiza distribuția datelor într-un set de date. Aceasta oferă o imagine grafică a frecvenței sau numărului de date care se încadrează în diferite intervale de valori. Pe baza analizei histogramei, puteți trage concluzii cu privire la natura datelor dvs. și puteți identifica caracteristici importante ale distribuției. De exemplu, puteți vedea dacă datele sunt distribuite normal, dacă există asimetrii sau dacă există valori extreme.
Când o distribuție are o coadă lungă spre partea dreaptă, este cunoscută sub numele de distribuție cu asimetrie spre dreapta sau distribuție pozitiv asimetrică. În distribuția cu asimetrie spre dreapta, concentrația punctelor de date spre coada dreaptă este mai mare decât cea din coada stângă.În distribuția cu asimetrie spre dreapta:
Media (Mean) > Median (Median) > Moda (Mode).
Aceasta înseamnă că: Media aritmetică (Mean) este mai mare decât valoarea medianei (Median). În timp ce moda (Mode) poate varia, de obicei este mai mică decât media (Mean). Aceste relații apar datorită prezenței valorilor mari sau extrem de mari în coada dreaptă a distribuției, care trage media în sus, dar nu afectează semnificativ mediană sau moda. O distribuție cu asimetrie spre dreapta este deseori denumită și "coadă grea" spre dreapta, deoarece există un număr semnificativ de valori extreme în partea dreaptă a distribuției, care împing media în sus.
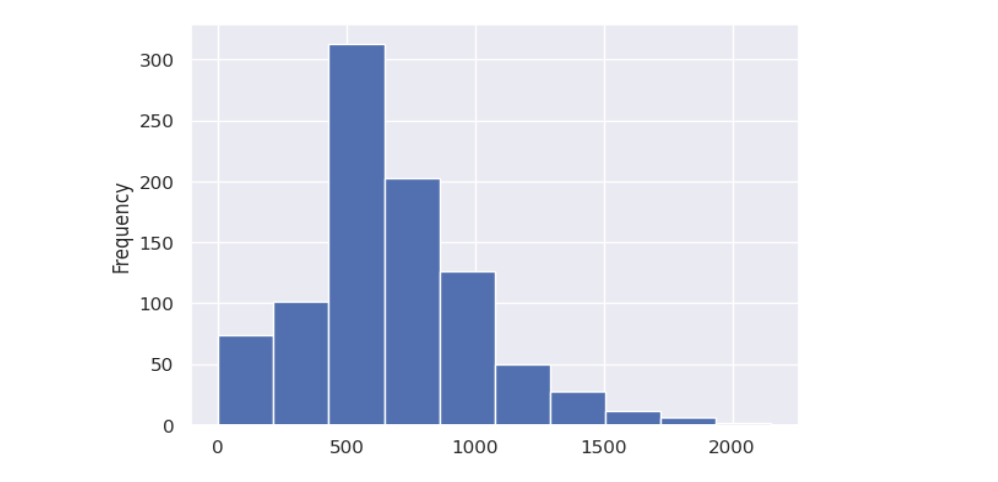
Histograma
Analiza descriptivă - Grafic univariat - Box plot
Outliners (valori aberante sau puncte extreme) sunt puncte de date care sunt semnificativ diferite de celelalte puncte dintr-un set de date. Aceste puncte sunt neobișnuit de mari sau mici în comparație cu majoritatea datelor și pot influența semnificativ analiza statistică sau modelele bazate pe date.
Există mai multe moduri de a defini și identifica valori aberante. Iată câteva dintre ele:
Definiție bazată pe deviație standard (z-score): Un outlier poate fi definit ca o valoare care se află la o anumită distanță (de obicei, mai mare 3 deviații standard) de la media datelor.
Definiție bazată pe percentile: Outlierii pot fi identificați ca valorile care se află în afara unui anumit interval de percentil, de obicei la cozi. De exemplu, valorile sub percentila 5 sau peste percentila 95 pot fi considerate outliers.
Metode grafice: O modalitate vizuală de a identifica valori aberante este de a utiliza grafice, cum ar fi graficele boxplot sau graficele Q-Q. Aceste grafice pot evidenția valorile care sunt departe de restul datelor.
Outlierii pot apărea din diferite motive, cum ar fi erori de înregistrare, variații naturale extreme sau chiar semnale reale, dar rare. Este important să gestionăm corect valorile aberante în analiza datelor. Opțiunile pentru tratarea outlierilor includ:
Eliminarea outlierilor: Acest lucru înseamnă să eliminați pur și simplu valorile aberante din setul de date. Aceasta poate afecta însă dimensiunea și caracteristicile setului de date.
Transformarea datelor: Puteți aplica o transformare matematică asupra datelor, cum ar fi logaritmul, pentru a face distribuția mai simetrică și pentru a atenua efectele valorilor aberante.
Înlocuirea outlierilor: În loc să eliminați outlierii, puteți înlocui valorile lor cu valori mai rezonabile, cum ar fi mediana sau media fără outlieri.
Modelarea robustă: Utilizați modele statistice sau algoritmii de învățare automată care sunt rezistenți la outlieri, ceea ce înseamnă că aceștia nu vor afecta semnificativ rezultatele modelului.
Este important să abordăm outlierii în funcție de contextul analizei noastre și să ne asigurăm că gestionăm corect influența lor asupra rezultatelor analizei noastre.

Boxplot
După cum putem observa din analiza datelor cu ajutorul graficul de tip boxplot, exista outliers in jurul valori de aprox. 1500, prin urmare toate valorile care sunt mai mari decat 1500 vor fi considerate direct outliers.